How to Design Distributed Systems: Consistency, Availability, Sharding & Replication

For CTOs, engineering leaders, and architects navigating real-world distributed systems trade-offs — includes an executive decision checklist at the end.
Distributed systems aren’t just “bigger applications.” They behave differently, and the CAP theorem makes that explicit. In this world, failure isn’t an edge case; it’s a constant companion.
Networks partition, nodes fail, and messages get dropped. Yet the system still has to serve customers, preserve transactions, and protect business outcomes.
Systems thinking helps tech leaders navigate these trade-offs, deliberately aligning consistency, availability, latency, and durability with business risk. This article distills five core concepts every architect, engineering lead, and CTO should have ready for design reviews and high-stakes decisions.
Summary
- CAP theorem forces a choice between consistency and availability when a network partition occurs; PACELC extends this to latency vs. consistency during normal operations.
- Consistency models (strong vs. eventual) should be chosen per operation, not per database — payments need linearizability; activity feeds can tolerate staleness.
- Leader election via Raft or Paxos prevents split-brain by requiring quorum agreement; never roll your own with row locks and heartbeats.
- Sharding enables horizontal scale across nodes; partitioning organizes data within a node — most systems need both, applied in the right sequence.
- Replication mode (sync vs. async) defines your durability guarantee; treating it as a deployment default is how confirmed orders disappear.
1. The CAP Theorem — and the Performance Lens of PACELC
The Core Idea
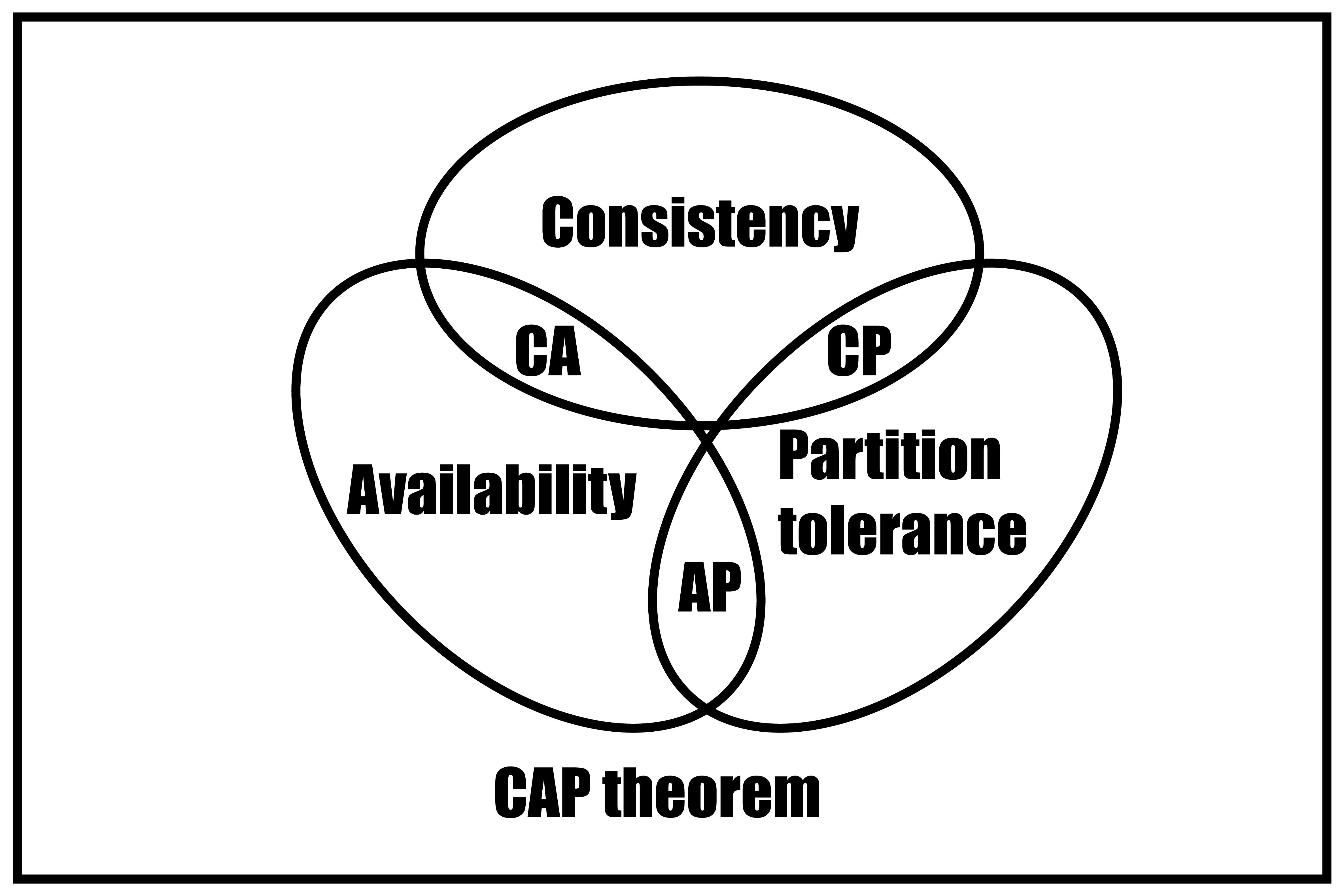
Eric Brewer’s CAP theorem says that during a network partition (P), a distributed system must choose between consistency (C) and availability (A). Since partitions are inevitable, the real decision is: fail to protect correctness (CP), or keep serving and reconcile later (AP).
That's the strict theorem. But day-to-day engineering reveals a third constant pressure: Performance. Stronger consistency requires extra round trips, quorum coordination, and write amplification — all of which erode latency and throughput even during normal operations. This is where PACELC extends the conversation:
- If Partition → choose Availability or Consistency
- Else → choose low Latency or Consistency
Together, CAP becomes your failure-time compass and PACELC becomes your everyday speedometer.
Why This Matters for the Business
Every architectural choice — database engine, replication topology, quorum size, caching strategy — implicitly fixes where your system sits on the CP/AP spectrum and the L/C tradeoff. Get it wrong and you either surface correctness failures (silent data mismatches) or availability failures (timeouts and error pages) — both of which translate directly to revenue impact and customer trust erosion.
The mapping to business context is straightforward:
- Payments and financial operations → CP. Accept timeouts rather than risk double charges or incorrect balances.
- Product search and recommendations → AP. Serve slightly stale results rather than failing.
- Homepage reads and content feeds → Prefer low latency; tolerate staleness within a bounded window.
A Cautionary Tale
A global retailer used synchronous, cross-region reservations—making checkout effectively CP. During a brief network disruption, the coordinator couldn’t reach one region, so checkout timed out for 18 minutes. Revenue took a hit, and p99 latency was high even on normal days due to quorum overhead.
They fixed it by keeping add-to-cart and soft-reserve regional and AP (using tokens), and reserving CP only for the final charge + hard-deduct step. Reads moved to local replicas with read-your-writes. Result: no repeat global outage, better latency, and only small, controlled reconciliations.
2. Consistency Models: Strong vs. Eventual
Key question: How fast should a write be visible everywhere? Delays like missing orders, lagging balances, or stale dashboards are usually design choices, not bugs.
Strong consistency (linearizability): Reads reflect the latest committed write immediately—best for correctness (payments, auth). Costs: higher latency and reduced availability during partitions due to coordination.
Eventual consistency: Replicas converge over time—best for scale and low-latency writes (feeds, metrics). Costs: temporary anomalies (duplicates, conflicts) that you must handle with idempotency/merge logic.
The Art of Mixing Models
Sophisticated systems don't choose one model globally — they apply each where it fits:
- Strong consistency for authentication, payments, inventory deductions, and any operation where a wrong answer has irreversible consequences.
- Eventual consistency for caches, analytics pipelines, activity feeds, and any read path where temporary staleness is acceptable.
The failure mode is treating consistency as a uniform database setting rather than a per-operation design decision.

A Costly Default
A fintech wallet ran eventual consistency by default. Under peak load, balances lagged for seconds, so users could submit multiple withdrawals before updates converged—leading to double spends, losses, and months of cleanup.
The lesson: consistency is never free, but the cost of the wrong model can far exceed the cost of engineering the right one.
3. Leader Election: Raft and Paxos Intuition
Why One Voice Matters
Distributed systems require coordination. Without a designated leader, multiple nodes can accept conflicting writes, reorder events, or produce divergent state. Leader election is the mechanism by which nodes reach consensus on who has the authority to drive replication and arbitrate decisions — even as machines fail and messages drop.
Two algorithms dominate production systems: Paxos, the foundational theorem-backed approach, and Raft, the clarity-first design built for understandability and operational transparency.
The Shared Foundation
Both algorithms share three non-negotiable properties:
- Quorum requirement — a majority must agree before any decision is committed, ensuring no two leaders can coexist simultaneously.
- Monotonic terms/epochs — every election increments a term counter, preventing stale or out-of-date nodes from reclaiming authority.
- Ordered log replication — state changes are recorded as a sequenced log, so all members converge on the same history regardless of when they rejoin.
Paxos vs. Raft: Decision, Risk, Mitigation
Paxos
| Decision | Use when integrating with existing consensus/coordination infrastructure (e.g., ZooKeeper-like systems) or when you’re standardizing on a proven Paxos/Multi-Paxos implementation. |
| Risk | Notoriously difficult to implement correctly; the original paper underspecifies implementation detail, making homegrown versions prone to subtle safety violations. |
| Mitigation | Use a proven library exclusively — never implement from scratch. Add fencing tokens to all downstream consumers to reject commands from deposed leaders. |
Raft
| Decision | Default choice for new systems. Cleaner state machine (Follower → Candidate → Leader), explicit log-matching rules, and simpler reconfiguration make it operationally transparent and easier to debug under pressure. |
| Risk | A stale candidate can increase election churn during instability, delaying commits and reducing availability. |
| Mitigation | Use etcd or Consul as your coordination layer. Tune heartbeat and election timeout intervals carefully for your network's round-trip characteristics. Pass monotonically increasing fencing tokens to all downstream systems so they can reject commands from deposed leaders. |

When DIY Election Goes Wrong
A scheduling team used a DB row lock + heartbeat for leader election. During a GC pause and a brief network blip, two nodes became “leader”, so a payment reconciliation job ran twice—causing duplicate payouts and a week of cleanup.
They switched to Raft via etcd and added fencing tokens. Leadership now requires a quorum and stale leaders are rejected, eliminating split-brain and making failovers predictable.
4. Sharding vs. Partitioning: Designing for Scale
Sharding and partitioning aren’t the same. The difference decides whether you can scale horizontally or get stuck at a single-node ceiling.
Partitioning (logical, one node): split data inside a single database instance (e.g., PostgreSQL orders by region or order_date). The engine routes queries; partitions still live on the same machine. Benefits: partition pruning, easier backups/maintenance, better index management. Limitation: no horizontal scale—one node remains the bottleneck.
Sharding (physical, many nodes): split data across multiple database nodes (e.g., users 1–1M on Shard A, 1–2M on Shard B). Each shard runs independently, so you scale by adding nodes. Trade-offs: cross-shard joins are hard/expensive, global transactions need coordination, shard key selection is critical (bad keys create hot spots), and rebalancing is operationally heavy.
Typical progression: start with partitioning for moderate scale; when data volume or write throughput outgrows a single node, introduce sharding. Mature systems often use both: partitioned tables inside each shard.
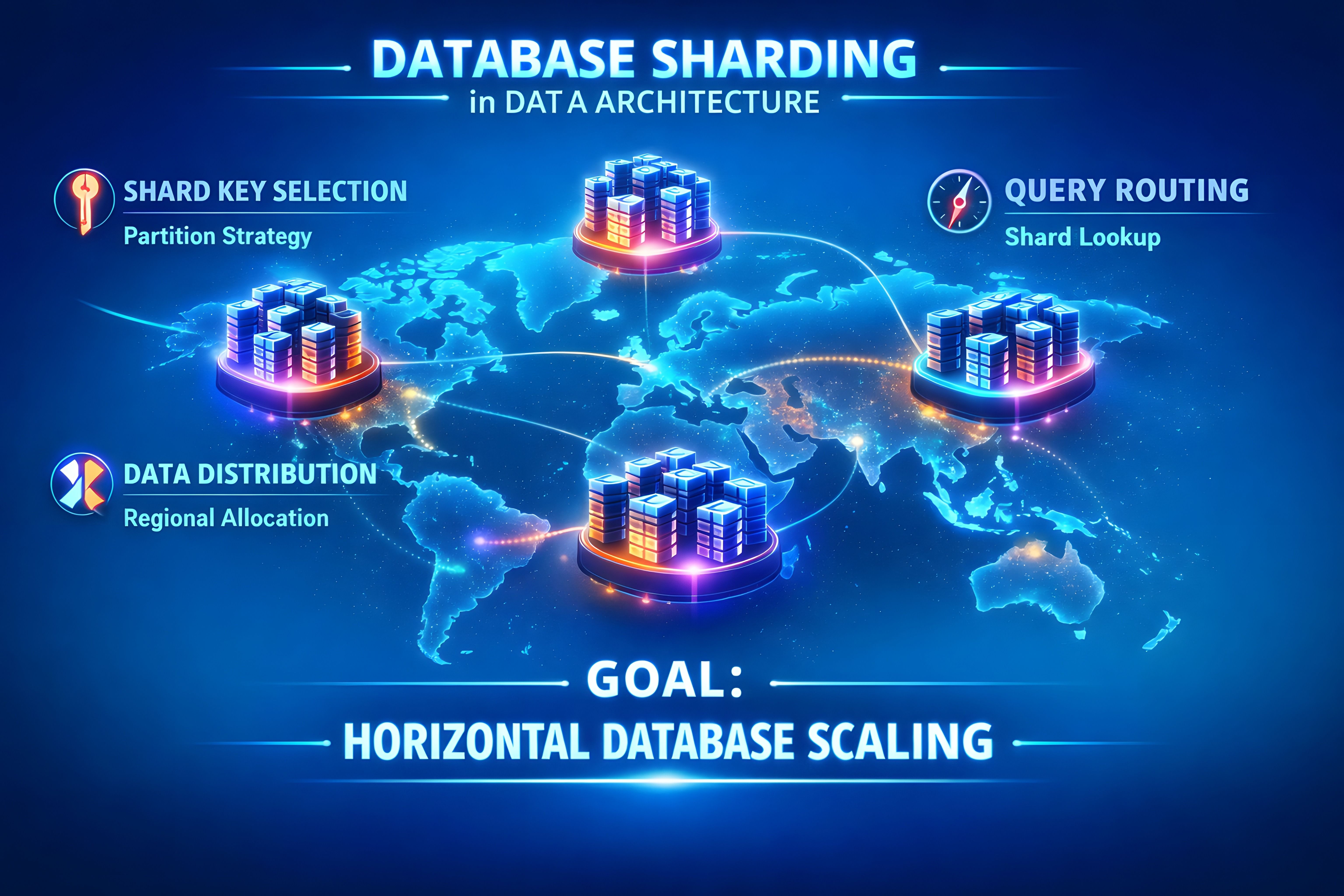
What happens if you wait too long: a large e-commerce platform used date-based partitioning. During a promo, writes piled into the “today” partition (a hot spot). Vertical scaling bought time, but couldn’t solve it. The fix required user-based sharding with consistent hashing, migrating billions of rows, and rewriting critical queries—turning a two-sprint decision into a multi-month program with downtime risk.
Bottom line: scale problems aren’t bugs—they’re architectural debt that compounds until it becomes an emergency.
5. Replication: Synchronous vs. Asynchronous
Replication improves durability by storing data on multiple nodes. But the replication mode isn’t a harmless default—it directly shapes failure behavior, write latency, and what your system can honestly guarantee to clients.
Sync vs. Async (Decision • Risk • Mitigation)
Synchronous replication (sync)
- Use when data loss is unacceptable: payments, auth state, inventory, compliance records
- Risk: higher write latency; p99 is tied to replica RTT and the slowest replica
- Mitigate: keep replicas close (adjacent AZs), use quorum writes (Kafka
acks=all, CassandraCL=QUORUM), monitor lag and evict degraded replicas
Asynchronous replication (async)
- Use when speed matters and some loss is acceptable: analytics events, activity logs, metrics, non-critical notifications
- Risk: a leader crash can permanently lose “confirmed” writes (ghost confirmations)
- Mitigate: document RPO, monitor lag, add circuit breakers—never use async for customer commitments (orders, payments)
Most real systems use a spectrum: tunables like Kafka acks=all and Cassandra CL=QUORUM, plus semi-sync modes, let you choose durability vs latency per workload.
Failure story: why this matters
A payments team ran async “because it was faster.” During peak traffic, the primary crashed before replicas caught up—so confirmed orders vanished, cascading into downstream fixes. The fix: move payment-critical writes to sync quorum replication, keep async only for lower-priority streams where loss is explicitly acceptable.
Bringing It Together: A Framework for Deliberate Architecture
These five concepts work together as one decision framework:
- CAP/PACELC sets the trade-offs under partitions and normal operation.
- Consistency models apply those trade-offs per operation.
- Leader election enforces coordination across nodes.
- Sharding/partitioning distributes data to scale safely.
- Replication defines durability across that distribution.
Systems age well when these choices are explicit, documented, and stress-tested—not left to defaults discovered during a 2 a.m. incident.
Top Questions on Distributed Systems Architecture
- What is PACELC? PACELC extends CAP beyond partitions. CAP only applies when the network splits (Partition): you must choose Availability (A) or Consistency (C). PACELC adds the everyday case: when there’s no partition, you still trade off Latency (L) vs Consistency (C).
In short: If P → A or C; Else → L or C.
- Strong vs. eventual consistency — when should I use which? Use strong consistency (linearizability) when mistakes are unacceptable—payments, auth, inventory, or regulated actions. Use eventual consistency when speed and availability matter more and brief staleness is fine—feeds, metrics, caches, analytics.
Key rule: choose per operation, not per database. Most real systems need both.
- What are the trade-offs between synchronous and asynchronous replication? Synchronous replication: a write is acknowledged only after replicas confirm—strong durability, but higher latency (tied to replica RTT and the slowest replica).
Asynchronous replication: acknowledge immediately and replicate later—fast, but there’s a durability gap; a leader crash can lose “confirmed” writes.
Rule: sync for customer commitments (payments, orders). async for non-critical/internal streams where some loss (RPO > 0) is explicitly accepted.
- What is the difference between Raft and Paxos? Both Paxos and Raft are consensus algorithms that ensure a single leader using quorums and monotonic terms. Paxos is older and powerful, but harder to implement and reason about. Raft is designed for clarity, with explicit state transitions and log rules.
Rule: for new systems, use Raft via etcd/Consul. Consider Paxos mainly when integrating with existing coordination infrastructure (e.g., ZooKeeper-like setups).
- When should I shard instead of partition? Start with partitioning to improve performance and maintenance within a single database, with low operational overhead. Move to sharding when a single node can’t handle your write load or data growth, or when you need separate failure domains—common signals are diminishing returns from vertical scaling or hot partitions during peaks.
Most important decision: shard key. Hash keys balance load; range keys help query locality but can create hot spots.
Executive Decision Checklist
Use this preliminary checklist when reviewing distributed system designs, evaluating vendor platforms, or conducting architecture reviews before major initiatives or migrations.
Business & Risk Alignment
- What is the business tolerance for data staleness on each critical operation? (Acceptable lag: milliseconds? Seconds? Minutes?)
- What is the acceptable data loss window (RPO)? Is any data loss permissible, and for which operations specifically?
- What is the required recovery time (RTO) if a node or region fails? Are current SLAs consistent with the replication and consensus configuration in place?
- Which operations must be CP (correctness-critical) and which can be AP (availability-critical)? Has this been documented per endpoint, not just per service?
Performance & Capacity
- What are the target p95 and p99 write latencies for each critical path? Do they account for quorum round-trips under the chosen replication mode?
- Has the shard key or partition strategy been validated against expected traffic distribution, including peak and skewed load scenarios?
- Are replica placement decisions (same AZ vs. cross-AZ vs. cross-region) explicitly matched to the latency budget and durability requirements for each workload?
Operational Readiness
- Is the replication mode (sync / async / semi-sync) documented and reviewed for every database and message broker in the critical path?
- Is leader election handled by a proven library (etcd, Consul, Patroni) with fencing tokens passed to all downstream consumers?
- Are idempotency keys, ETags, and compensating transactions in place for all operations that may be retried across partition or failover boundaries?
- Has the system been chaos-tested against leader failure, replica lag, and network partition scenarios — not just against expected traffic load?
Governance
- Are these architectural decisions version-controlled and reviewed as part of the engineering change process, not accepted as deployment-time defaults?
- Does the on-call runbook explicitly state where each service sits on the CP/AP and L/C spectrum, so engineers can reason correctly under pressure at 2 a.m.?


AI-driven Data Operations: How DataVolve Strengthens the Post-migration Journey


