How to Optimize Costs in Databricks

In the era of big data, efficient cost management is crucial for leveraging data analytics platforms like Databricks. Whether you're a startup or an enterprise, optimizing costs without compromising performance is essential. Here are some key strategies to help you manage and reduce costs while maximizing the benefits of Databricks.
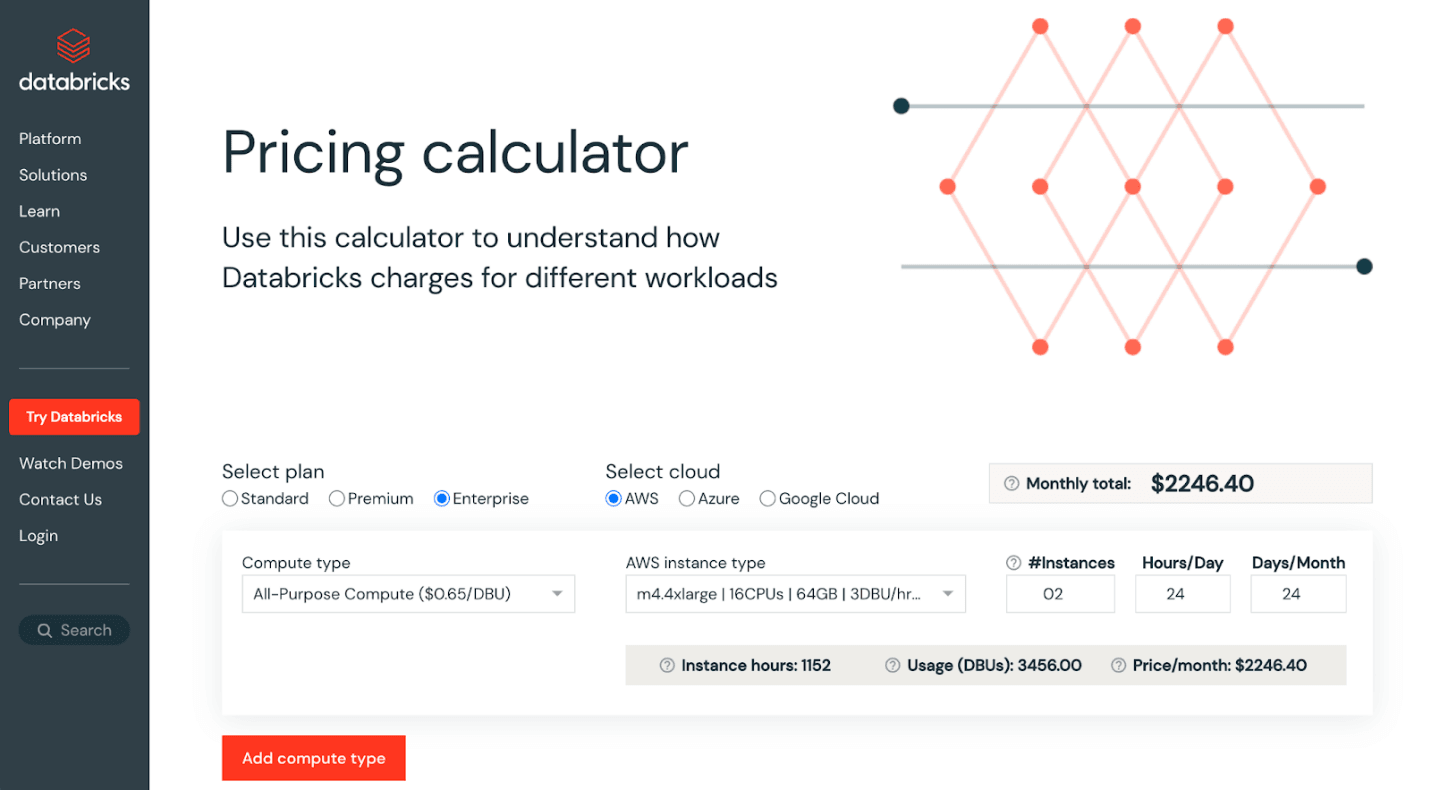
Use DBU calculators
With Databricks' DBU calculator, you can estimate the cost of running specific workloads and identify areas for cost optimization. To determine the most cost-effective configuration for your workload, you can play around with different cluster sizes, instance types, and subscription plans.
By using the DBU calculator, you can better understand how factors such as the number of nodes, memory size, and disk size can affect your overall costs, allowing you to make informed decisions to reduce costs and optimize workloads.
Enable autoscaling
Databricks provides an autoscaling feature that can help you save costs by allocating resources based on workload demands. With this feature in place, you only pay for the resources you need - you won't overprovision or underprovision the resources needed to handle your workload.
Autoscaling works by automatically adjusting the size of your cluster based on workload demand. In times of low workload demand, cluster size is reduced to minimize costs. As demand increases, the cluster size is increased to ensure optimal performance.
To configure Autoscaling in Databricks, you'll need to specify the minimum and maximum number of nodes in your cluster, along with an Autoscaling policy that will determine cluster size according to workload demand. In addition, you can configure time-based Autoscaling, which adjusts the cluster size based on the time of day or day of the week.

Leverage Cluster Policies
Cluster policies in Databricks allow you to control and manage the configuration of clusters. By defining policies, you can:
- Restrict cluster sizes to prevent oversized clusters.
- Set termination policies to shut down idle clusters automatically.
- Enforce cost-saving configurations such as spot instances.
How to Implement:
- Navigate to the Admin Console in Databricks.
- Define and apply policies under the Cluster Policies section.
- Educate your teams on using pre-defined cluster configurations.
Use Auto-Termination
Setting auto-termination for clusters is a straightforward way to avoid unnecessary costs. Clusters that are not in use should automatically shut down after a specified period of inactivity.
How to Implement:
- When creating a cluster, enable the Auto-Termination feature.
- Set the inactivity period according to your usage patterns (e.g., 30 minutes).
Optimize Cluster Sizing
Selecting the appropriate cluster size based on workload requirements can significantly reduce costs. Over-provisioning leads to wasted resources, while under-provisioning can hinder performance.
How to Implement:
- Analyze workload patterns and size your clusters accordingly.
- Use the Databricks Job Scheduler to automate the scaling of clusters based on workload demands.
Utilize Spot Instances
Spot instances can provide significant cost savings, as they are often available at a fraction of the price of on-demand instances. However, they can be terminated by the cloud provider, so they are best suited for fault-tolerant workloads.
How to Implement:
- Enable Spot Instances in your cluster configuration.
- Use a mix of on-demand and spot instances to balance cost and reliability.
Monitor and Analyze Costs
Regular monitoring and analysis of your Databricks usage can help identify cost-saving opportunities. Databricks provides several tools for this purpose.
How to Implement:
- Use Databricks Cost Management features to track spending.
- Set up budgets and alerts to monitor usage and get notified of anomalies.
- Regularly review cost reports and optimize based on insights.
Optimize Data Storage
Efficient data storage can also lead to cost savings. Delta Lake, the storage layer that brings ACID transactions to data lakes, can help optimize storage costs.
How to Implement:
- Use Delta Lake for efficient data storage and management.
- Apply data compaction and optimize operations to reduce storage footprint.
- Archive cold data to cheaper storage options.
Leverage Databricks' Built-In Features
Databricks offers several built-in features to help optimize costs:
- Photon Engine: Provides faster query performance and lower costs.
- SQL Analytics: Optimize SQL workloads for cost-efficiency.
- Unity Catalog: Provides centralized governance and cost control. How to Implement:
- Enable the Photon Engine in your Databricks environment.
- Utilize SQL Analytics for your SQL workloads.
- Use the Unity Catalog for efficient data governance.
Optimize data processing workflows
- Partitioning
You can reduce costs by optimizing your data processing workflows. A good strategy is to partition huge datasets into smaller, easily manageable chunks that can be processed in parallel. By partitioning your data, you can reduce the time required to process large datasets and reduce your workload's cost. - Caching
Caching is another useful technique, allowing you to save frequently accessed data in memory for fast retrieval and reuse. - Predicate push down technique
Cost-saving techniques such as filter pushdown can also be used to reduce costs. The goal of this technique is to push filters down to the data source, which may reduce the amount of data that needs to be transferred and processed. Minimizing data processing steps will reduce your workload's overall cost.
Using optimized file formats and using appropriate storage tiers
Reduce storage costs by using compressed formats like parquet,etc. and storing rarely used data in lower-cost tiers.


Conversational AI in Data Warehouses

