5 Pragmatic Engineering Practices That Build High-Performing Teams
For engineering leaders and senior practitioners building systems that must scale, last, and evolve under pressure.
Engineering culture is not defined by posters or principles. It is revealed in daily decisions: how pull requests are reviewed, how debt is tracked, how tests are designed, and how delivery pipelines are interpreted. Teams that ship reliably are rarely separated by talent alone. They are separated by discipline applied consistently across five practices: code reviews, technical debt management, scope control, testing strategy, and CI/CD design.
This article looks at those practices not as theory, but as practical levers that shape delivery speed, resilience, and long-term engineering effectiveness.
1. Code Reviews That Prevent Production Risk, Not Just Bugs
Why Weak Code Reviews Become Expensive Later
Many teams treat code reviews as a final quality gate: catch a bug, approve the style, and merge the change. That is too narrow. Reviews focused solely on surface-level correctness miss the issues that matter most in production: lack of idempotency, untested failure paths, limited observability, and gradual architectural drift.
For senior engineers and tech leads, code review is one of the highest-leverage moments in the delivery process. It is where design intent gets tested, architecture is reinforced or weakened, and engineering judgment is taught in public. Done well, a review is a compact design discussion centered on a real change.
What High-Impact Code Reviews Should Actually Check
Strong reviews go far beyond syntax. Does the change solve the right business need? Has scope expanded quietly? Are service boundaries respected? What happens under retries, partial failures, or schema changes? Are structured logs, useful metrics, and alerts in place?
Author discipline matters just as much. Small, focused pull requests with clear descriptions, explicit assumptions, and rollback paths are not overhead. They are what make good reviews possible.
The enabling process is simple: automate formatting and vulnerability scanning, set expectations for review latency, and measure post-merge incidents as a signal of review quality. Humans should review judgment, not braces.
2. Technical Debt Management: How Strong Teams Stay Fast Over Time
Good Technical Debt vs. Bad Technical Debt
Technical debt becomes unhelpful when it means everything and therefore explains nothing. A better model is to treat it as a portfolio.
Good debt is intentional. A team chooses a simpler approach to validate demand, meet a hard deadline, or reduce time-to-learning. The trade-off is documented, owned, and scheduled for repayment.
Bad debt is different. It appears as duplicated logic, missing tests, hidden coupling, skipped refactoring, and quick fixes with no owner or plan. The issue is not the shortcut itself. It is the lack of intentionality.
How to Make Technical Debt Visible and Actionable
Unmanaged debt always surfaces eventually. It shows up as slower pull request cycles, rising change failure rates, recurring incidents, and modules that engineers avoid touching. By that point, the interest is already compounding.
The response should be operational. Maintain a visible debt register with owners and due dates. Reserve regular sprint capacity for paydown. Use proven patterns such as the Strangler Fig for legacy boundaries and the Boy Scout Rule for incremental improvement. Add architecture fitness checks to stop silent structural decay.
Debt is not the enemy. Invisible debt is.
3. YAGNI vs. Overengineering: How to Build for Today Without Slowing Tomorrow
The Cost of Complexity That Is Not Solving a Real Problem
Overengineering usually comes from good intentions. Teams anticipate future scale, integrations, and product variants, then add abstraction layers, configuration knobs, or generic frameworks before the business has validated the need.
That complexity is rarely free. It increases cognitive load, slows onboarding, widens incident blast radius, and raises cloud and operational costs. YAGNI — You Aren’t Gonna Need It — is not anti-design. It is disciplined scope control. Build for validated needs now, while keeping the system extensible later.
Practical Heuristics to Avoid Overengineering
A few rules work well. Do not generalize until at least three real variants exist. Design for concrete use cases, not imagined futures. Every abstraction should have an owner and a reason to exist. If neither is clear, it is probably speculative.
The best balance is a minimal viable architecture with strong observability, clear contracts, and migration seams. That gives teams room to evolve without paying for complexity too early.
4. Modern Testing Strategy: Rethinking the Testing Pyramid for Distributed Systems
Why the Classic Testing Pyramid Needs an Update
The Testing Pyramid still holds in principle: many unit tests, fewer integration tests, and a small set of end-to-end tests. But modern systems introduce challenges the original model did not fully account for: microservice contracts, asynchronous flows, feature flags, and independent deployments.
Without adapting, teams drift into predictable anti-patterns. Some rely too heavily on UI and end-to-end testing. Others have many unit tests but weak service-level validation. Both create blind spots.
What a Better Enterprise Testing Strategy Looks Like
The base remains the same: fast, isolated unit tests around domain logic. These should make up the majority of the suite.
The middle layer matters more than many teams realize. Service and component tests validate realistic behavior using test containers, in-memory brokers, and controlled dependencies. Contract tests are essential in distributed systems because they protect producer-consumer assumptions across independently released services.
End-to-end tests should remain a thin slice focused on critical journeys such as order placement, allocation, and notification. Non-functional tests such as performance, resilience, and security should be explicitly designed into the strategy, not bolted on later.
Confidence comes from balance, not from maximizing one layer.

5. CI/CD as a Feedback Loop: How High-Performing Teams Learn Faster
Why CI/CD Should Be Designed for Learning, Not Just Deployment
The most limiting view of CI/CD is to see it as a deployment mechanism. Its real value is feedback. Every build result, test outcome, deployment event, and post-release metric tells the team whether an engineering decision was sound.
Teams that treat CI/CD only as automation optimize for movement. Teams that treat it as a feedback loop optimize for learning. That learning is what sustainably improves speed.
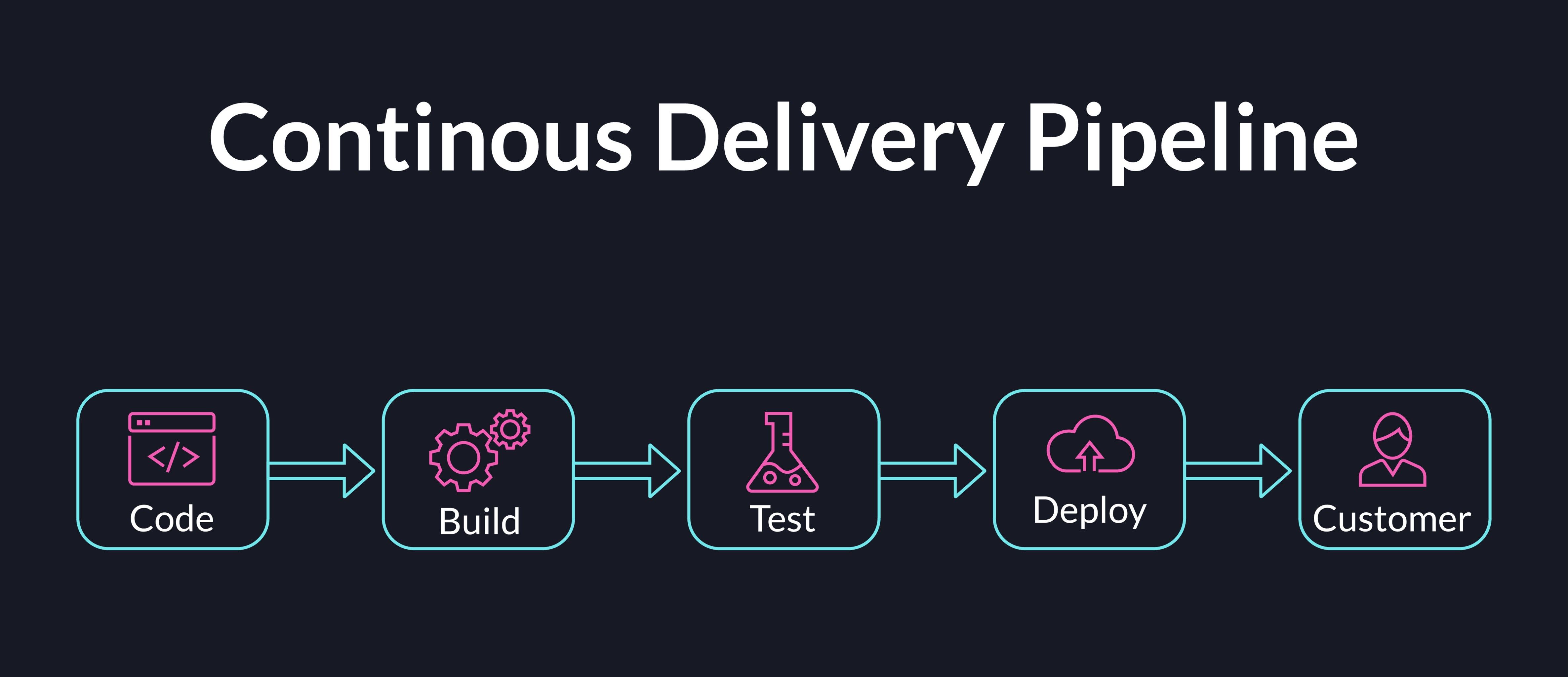
How to Build Pipelines That Improve Engineering Decisions
A useful pipeline answers three questions on every change: Is this safe? Is it better than before? Should we continue or stop?
That requires fast, meaningful signals. If CI takes too long, feedback is stale. If performance checks run weekly instead of near deployment, regressions surface too late. If alerts are noisy or unclear, confidence drops.
Strong pipelines are designed around action, signal, interpretation, and correction. They combine fast pre-merge checks with post-deployment signals such as latency, error rates, rollback frequency, and service health. When those signals are clear, CI/CD becomes an engineering compass rather than automation glue.
Why These Engineering Practices Compound Over Time
These five practices are not independent. Code reviews reinforce architecture. Technical debt discipline keeps systems changeable. YAGNI prevents unnecessary complexity from slowing delivery. Testing improves confidence at the right layers. CI/CD turns every change into a learning opportunity.
Their value compounds. The difference between a codebase that accelerates delivery and one that resists it is rarely a single major decision. It is the cumulative effect of these smaller, repeated choices.
Engineering culture is built that way, too. The best teams are not the ones that move fastest in week one. They are the ones still moving confidently in year three.
Explore our Engineering Services and Performance Engineering practice.


How to Assess Data Modernization Readiness Before You Commit



