How to Build High-Performance Data Ingestion Pipelines

Building a high-performance data ingestion pipeline is one of the most consequential decisions in any modern data platform. Whether the workload is real-time streaming with Apache Kafka, batch ETL on Apache Spark, or a hybrid setup feeding both a data lake and a data warehouse, the ingestion layer decides how fresh, reliable and useful downstream analytics actually are. The global data pipeline tools market is growing at around 22% a year, from roughly $11.2 billion in 2024 to $13.7 billion in 2025. This guide walks through what data ingestion pipelines are, when to choose batch versus streaming, and the practical steps for designing pipelines that scale.
What is a data ingestion pipeline?
Data ingestion is the process of collecting and importing data from many sources into a destination system where it can be processed, stored or analysed. Sources typically include transactional databases, log files, IoT devices, SaaS APIs, event streams, spreadsheets and cloud storage. Destinations include data warehouses (Snowflake, Redshift, BigQuery), data lakes (S3, ADLS, GCS) and lakehouse platforms (Databricks, Delta Lake, Apache Iceberg). A data pipeline is the wider system that moves data from those sources to those destinations, applies transformations, and delivers it to consumers such as BI tools, machine learning models, AI agents and operational applications.
Batch vs streaming: choosing the right ingestion pattern
Most pipelines fall into one of two models, and the choice shapes every decision that follows.
Batch ingestion moves data at scheduled intervals: hourly, nightly, or after a trigger event. It is simpler to operate, easier to test, and well suited to end-of-day reporting, data warehouse loads and large historical analytics. Apache Spark is the workhorse here.
Streaming ingestion moves data continuously, event by event, with sub-second to single-digit-second latency. It suits fraud detection, real-time personalisation, IoT telemetry, and any feature that depends on fresh data. Apache Kafka is the de facto messaging backbone; Apache Flink and Spark Structured Streaming are the most common processing engines.
Many real-world platforms combine both. The Lambda pattern runs separate batch and streaming pipelines and merges results. The Kappa pattern handles everything as streams. The Medallion architecture popularised by Databricks moves data through bronze, silver and gold layers using one engine for both modes.
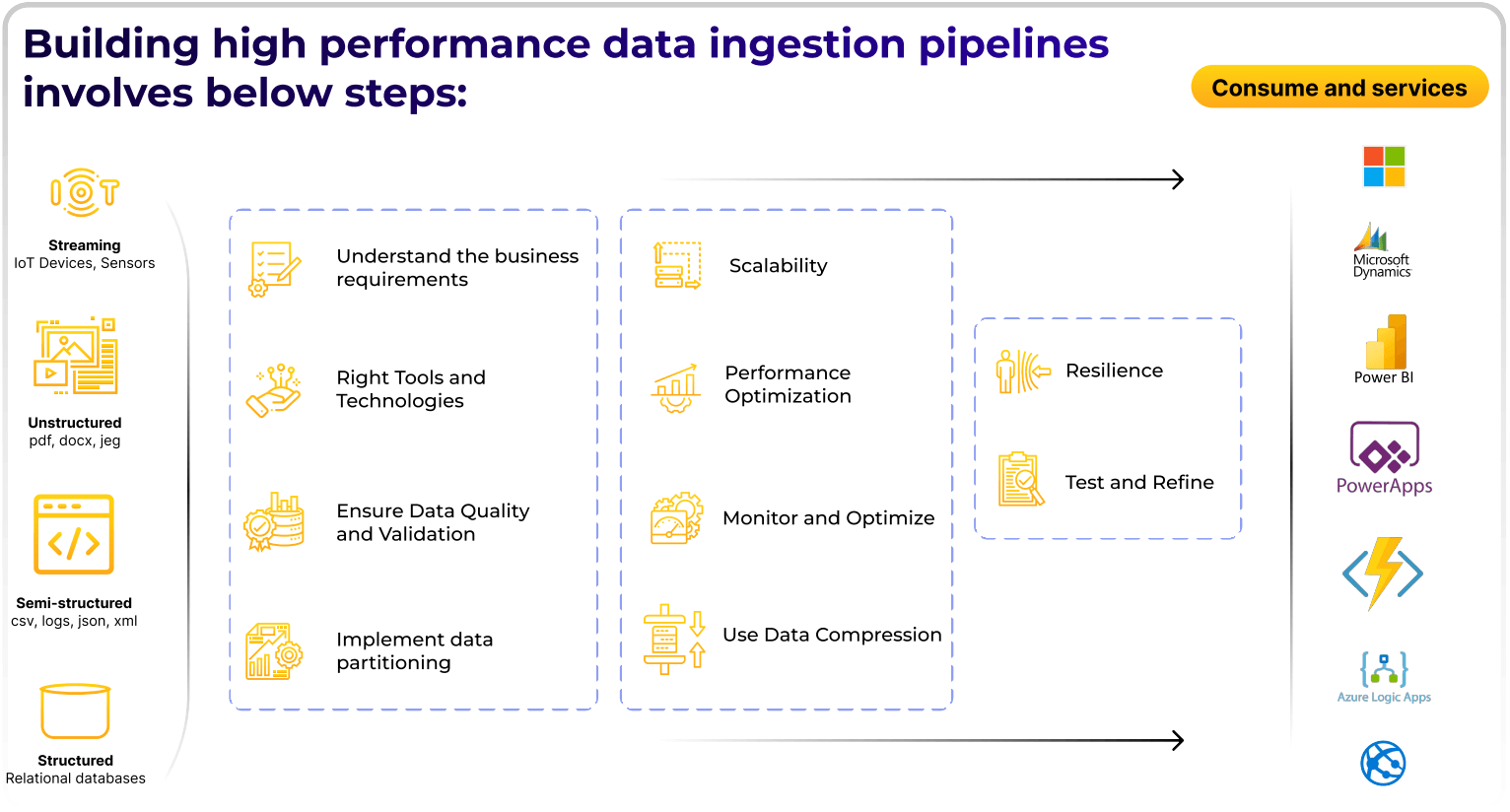
Step 1: Define business requirements first
Before any tooling choice, get clear on what the pipeline is actually for.
- Identify data sources and destinations. Map every source system, the data shape (structured, semi-structured, streaming), and where it lands.
- Define volume and velocity. How much data, how often, and at what burst rate?
- Specify data quality requirements. Decide upfront what accuracy, completeness and consistency the downstream consumers need.
- Set latency and throughput SLAs. How fresh does data need to be, and how many events per second does the pipeline have to handle at peak?
Pipelines fail more often from vague requirements than from technical limits. Set these numbers explicitly and use them as the acceptance criteria for every later decision.
Step 2: Design for scalability and resilience
A high-performance pipeline scales horizontally and recovers from failure without losing data or duplicating it.
- Horizontal scalability. Add more workers, partitions or brokers as volume grows, without rebuilding the pipeline.
- Replication. Replicate data across nodes and zones so a single failure does not lose events.
- Retries and dead-letter queues. Plan for poison messages and network failures up front.
- Idempotency. Design transformations so that re-running a batch or replaying an event produces the same result. This is what makes the pipeline safe to recover.
- Exactly-once semantics. Pair an idempotent sink with idempotent producers and consumers where the business case requires it. Kafka and Spark Structured Streaming can achieve this when configured correctly.
Step 3: Choose the right data ingestion tools and frameworks
The right stack depends on the workload. Common combinations:
- Ingestion and messaging: Apache Kafka, Amazon Kinesis, Google Pub/Sub, Apache Flume, Redpanda.
- Processing frameworks: Apache Spark and Spark Structured Streaming for unified batch and streaming, Apache Flink for low-latency stateful streaming, dbt for in-warehouse transformation.
- Storage: Snowflake, BigQuery or Redshift for warehouses; S3, ADLS or GCS for data lakes; Delta Lake, Apache Iceberg or Apache Hudi for lakehouse table formats; MongoDB or Cassandra for NoSQL workloads.
- Orchestration: Apache Airflow, Dagster or Prefect for scheduling and dependency management.
Cloud-native ELT (Extract, Load, Transform) has displaced traditional ETL for most cloud warehouse workloads, because storage and compute are now cheap enough to load raw data first and transform inside the warehouse.
Step 4: Plan data partitioning and parallelism
Partitioning and parallelism are how pipelines move from "works on a sample" to "handles production volume". Partitioning strategies:
- Key-based. Related records (for example, by customer ID) processed by the same worker. Good for stateful operations.
- Range. Data split by ranges of a numeric or date field. Useful for time-series workloads.
- Hash-based. A hash function distributes data evenly across partitions. Best when uniform distribution matters more than locality.
Parallelism types:
- Task parallelism. A single job split into independent subtasks running concurrently.
- Data parallelism. The same operation applied to different data shards in parallel across nodes.
Keep partition sizes balanced. A skewed partition becomes the slowest worker, and the whole pipeline waits for it.
Step 5: Use data compression and the right storage formats
Compression and format choice reduce storage cost, cut network bandwidth and improve query performance, often by an order of magnitude.
- Gzip offers good compression ratios for text-based formats like JSON, CSV and log files.
- Snappy prioritises speed and is the usual default with Kafka and Parquet for low-latency streaming.
- Zstandard (Zstd) sits between the two, with strong ratios and competitive speed.
For analytics workloads, columnar formats like Apache Parquet or Apache ORC outperform row-based formats such as CSV or JSON, especially when combined with predicate pushdown and partition pruning. Step 6: Build in data quality and observability from day one Validation cannot be an afterthought. By the time bad data reaches a dashboard, the cost of fixing it has multiplied.
- Schema validation. Reject or quarantine records that do not match expected types and constraints.
- Deduplication. Detect and handle duplicates at the ingest boundary, not in the warehouse.
- Data lineage. Track where each record came from and how it has been transformed. OpenLineage and DataHub are now common standards.
- Data observability. Monitor freshness, volume, schema drift and distribution. Treat data the way SREs treat production services.
Step 7: Monitor, test and refine A pipeline is not "done" at first go-live. The numbers that matter in production:
- Throughput. Events or rows per second.
- End-to-end latency. From source event to consumable record.
- Error rates and retry counts. Per stage and per source.
- Resource utilisation. CPU, memory, network and storage on each component.
Test discipline matters as much as monitoring. Unit-test individual transformations. Run integration tests against representative data volumes. Use synthetic load tests to validate scaling before peak season, not during it.
In summary
High-performance data ingestion pipelines are less about picking a single "best" tool and more about matching architecture to workload. Clear business requirements, the right batch-versus-streaming decision, sound partitioning, sensible compression, strong validation and steady observability are what separate pipelines that survive production from those that get rewritten every six months.
The best data pipelines are not just fast; they are resilient, observable and designed to keep enterprise decisions moving with confidence.


Conversational AI in Data Warehouses


